Der Pharma Chemica
Journal for Medicinal Chemistry, Pharmaceutical Chemistry, Pharmaceutical Sciences and Computational Chemistry
ISSN: 0975-413X
Abstract
Validation Method Used In Quantitative Structure Activity Relationship
Author(s): Naveen K. Mahobia,Roshan D. Patel,Naheed W. Sheikh, Sudarshan K. Singh,Achal Mishra, Ravindra DhardubeyQuantitative structure activity relationship is study of relationship between physiochemical (independent) properties and biological (dependent) activity of bioactive molecules. It plays an important role in the drug discovery and development and involves steps including data preparation, data analysis, and model validation. Validation is important process in QSAR analysis. After correlation between, independent and dependent variable with the help of various statistical methods the model will developed now that model should be validated. Various types of statistical methods are used in QSAR analysis such as principle component analysis, cluster analysis, simple linear regression, multiple linear regressions, partial least square, K-Nearest Neighbor classification, neural network, logistic regression and many others. After the development of model it is necessary to find out how predictive a model is that is concept of validation, which finds out the accuracy of model to predict the activity of bioactive compound. Validation is important in QSAR analysis since it is not necessary that a good model always have a good ability to predict the activity of respective bioactive agents. Validation involves external and internal validation to predict external and internal predictivity respectively. Cross validation (K-fold cross-validation, leaveone- out cross-validation, leave-ten-out or leave-many-out cross-validation), bootstrap method, randomization, jack- knife, hold out validation methods are used for internal validation to predict the internal validity. In the external validation data selection plays an important role because the distribution of the properties (variables) should be uniform in both of the sets that are test set and training set. There are various method through which the original data can accurately divided involving manual selection, randomization, sphere exclusion method and other methods such as onion design, cluster analysis, factorial, full factorial experiment, self organizing map(SOM), and principle component analysis. With the help of various statistical measures such as n, k, df, r2, q2, pred_ r2 etc. and there recommended values we can easily validate the model
Select your language of interest to view the total content in your interested language
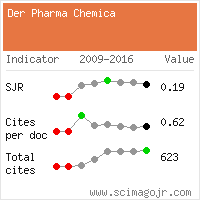
Google Scholar citation report
Citations : 15261
Der Pharma Chemica received 15261 citations as per Google Scholar report
Der Pharma Chemica peer review process verified at publons